

客服橙子

微信二维码

13360330306
cz@payue.com
“中国电信人工智能研究院”官方公众号今天宣布,中国电信人工智能研究院成功完成国内首个基于全国产化万卡集群训练的万亿参数大模型,并正式对外开源首个基于全国产化万卡集群和国产深度学习框架训练的千亿参数大模型 —— 星辰语义大模型 TeleChat2-115B。
这是由中国电信集团 CTO、首席科学家、中国电信人工智能研究院(TeleAI)院长李学龙教授带领团队完成的又一项里程碑式的重要科研成果,标志着国产大模型训练真正实现全国产化替代,正式进入全国产自主创新、安全可控的新阶段。TeleChat2-115B 基于中国电信自研的天翼云“息壤一体化智算服务平台”和人工智能公司“星海 AI 平台”训练完成,在保证训练精度的前提下利用多种优化手段提升模型训练效率和稳定性,实现了 GPU 同等算力计算效率的 93% 以上,同时模型有效训练时长占比达到 98% 以上。
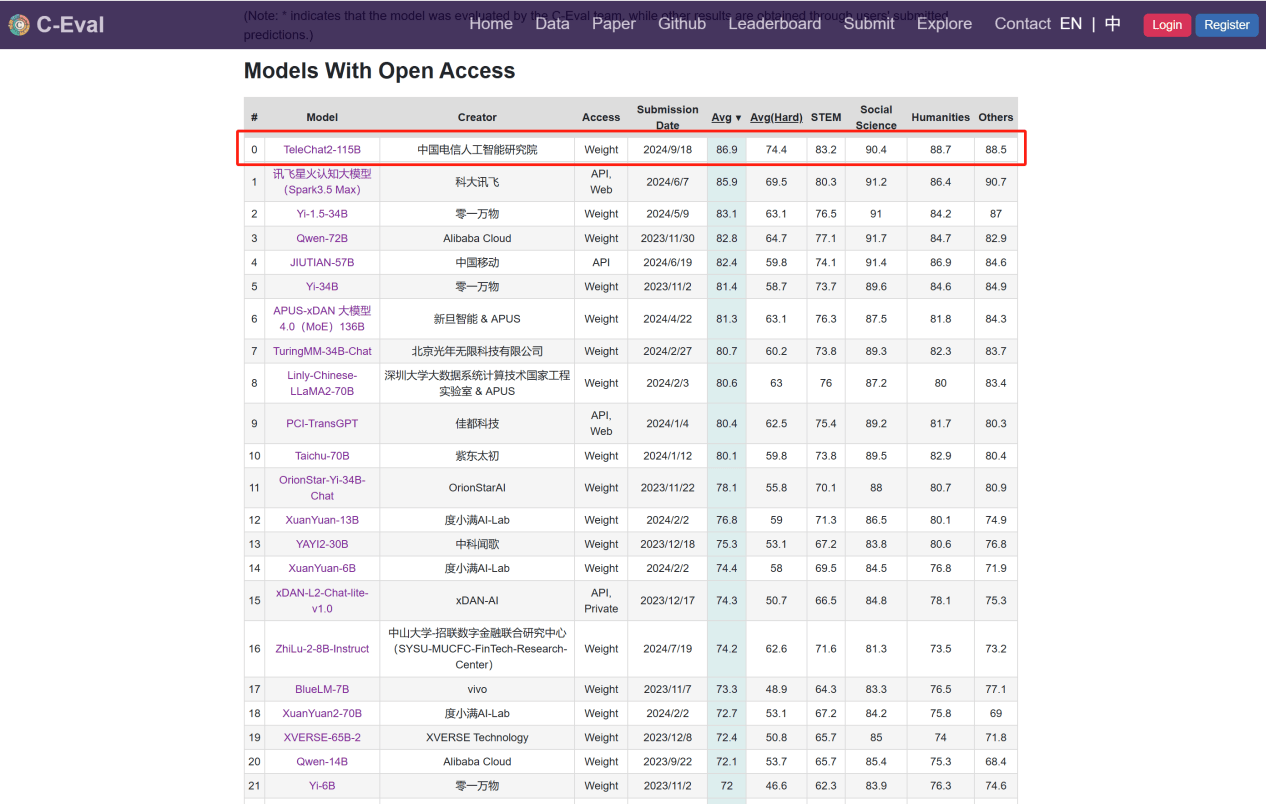
在今年5月的 OpenCampass 测试榜单中,TeleChat 系列模型的逻辑推理能力名列开源大模型榜单第一。作为新一代版本,TeleChat2-115B 在9月最新公布的 C-Eval 评测 Open Access 模型综合榜单中,以 86.9 分的成绩排名第一。其通用能力较 TeleChat 系列模型提升近 30%,特别是在工具使用、逻辑推理、数学计算、代码生成和长文写作等方面能力均有大幅提升。
TeleChat2在模型训练与数据构建方面的研究经验
针对超大参数模型训练,TeleAI 采用了大量小模型进行 Scaling,进而验证不同模型结构的有效性。同时,在数据配比方面,基于小模型实验结果反馈,采用回归预测模型,得到较优数据配比。
基于以上策略,能够大幅提升大参数模型最优方案的搜寻效率。另外,在后训练退火阶段,TeleAI 通过大量实验验证探索到了退火最佳数据量和最佳配比,以及学习率变化方式等,进一步提升了模型训练效果。
在 Post-Training(后训练)方面,TeleAI 首先针对数学、代码和逻辑推理等内容合成了大量问答数据,用于 SFT(监督式微调)第一阶段模型训练。其次采用迭代式更新策略,使用模型对 Prompt(提示词)数据进行指令复杂性提升与多样性扩充,通过模型合成和人工标注提升答案质量,并利用拒绝采样获取优质 SFT 数据及 RM(奖励模型)代表性数据,用于 SFT 训练和 DPO(偏好对齐)训练,以及模型效果迭代。
TeleAI自研语义大模型获多项权威赛事第一名
连获中国计算语言学大会(CCL2024)挑战赛两项冠军:TeleAI 在 CCL2024 大会上获得中文空间语义理解评测和古文历史事件类型抽取评测两项第一名。其中,在古文历史事件类型抽取评测任务挑战赛中,更是在所有子任务均取得第一名的情况下获得了综合排名第一。
NLPCC2024 中文议论文挖掘(Shared Task5)挑战赛冠军:TeleAI语义团队基于上下文学习策略对大模型进行优化,通过利用从粗粒度到细粒度的 Prompt 设计、多模型的投票机制等手段,进一步提高了模型准确率和鲁棒性,最终以领先第二名将近 3 分的绝对优势排名第一。
开源共享,引领创新
TeleChat2-115B 的开源标志着大模型国产化迈进了又一个新征程。作为最早布局并首先开源大模型的央企机构,TeleAI 积极通过开源推动大模型技术的不断进步,并持续推动和引领技术创新向产业落地快速跃迁。